BIDS annotation quickstart¶
This tutorial provides a step-by-step guide to creating a JSON sidecar containing the annotations needed to document your BIDs dataset events. See HED annotation quickstart for guidelines on what annotations to choose.
We assume that your dataset is already in the BIDS BIDS Brain Imaging Data Structure format and focus on the mechanics of event annotation in BIDS using HED.
General strategy for machine-actionable annotation using HED.
The goal is to construct a single events.json sidecar file with all the
annotations needed for users to understand and analyze your data.
You will put the finished annotation file at the top level of your dataset.
The approach that we will use is to create a template file from an events.tsv file
in your BIDS dataset using the online tools available at
hedtools.org/hed.
You can then edit this JSON file directly using a text editor to insert data descriptions and HED annotations.
You also have the option of converting this JSON template to a spreadsheet template for editing convenience as described below in Spreadsheet templates.
Warning
Although the HED web tools base the template on the information extracted from a single
events.tsv file, this will be sufficient to produce a good template for most datasets.
For datasets with widely-varying event files, you should use the
validate_bids_dataset.ipynb
Jupyter notebook version rather than the online tools.
The Jupyter notebook consolidates information from all of the events.tsv files in the dataset
to produce a comprehensive JSON sidecar template.
The examples in this tutorial use an
abbreviated version
of the events.tsvfile from subject 002 run 1 from
ds003645:Face processing MEEG dataset with HED annotation
dataset on OpenNeuro.
A reduced version of this dataset
eeg_ds003645s_hed
is also available.
How HED works in BIDS¶
Before getting into the details of event annotation, we briefly explain how BIDS represents events.
BIDS event files¶
BIDS events are time markers with associated metadata stored
in tabular form in events.tsv files.
Each events.tsv file is associated with a particular data recording file
by its filename using the BIDS naming scheme and by its location
within the BIDS dataset directory tree.
For example, the file sub_002_task-FacePerception-run-1_events.tsv
gives event markers relative to the EEG data file
sub_002_task-FacePerception-run-1_eeg.set located in the same directory
because the file names match up to the last underbar.
The following is an excerpt of a BIDS events file showing its tabular structure.
A simplified excerpt from a BIDS events file.
onset |
duration |
sample |
event_type |
face_type |
rep_status |
trial |
rep_lag |
value |
stim_file |
|---|---|---|---|---|---|---|---|---|---|
0.004 |
n/a |
1 |
setup_right_sym |
n/a |
n/a |
n/a |
n/a |
3 |
n/a |
24.2098 |
n/a |
6052 |
show_face |
unfamiliar_face |
first_show |
1 |
n/a |
13 |
u032.bmp |
25.0353 |
n/a |
6259 |
show_circle |
n/a |
n/a |
1 |
n/a |
0 |
circle.bmp |
25.158 |
n/a |
6290 |
left_press |
n/a |
n/a |
1 |
n/a |
256 |
n/a |
… |
BIDS requires that all events.tsv files have an onset column containing the time (in seconds)
of the event relative to the start of the data recording to which it is linked.
BIDS also requires a duration column giving the duration in seconds of the event
associated with this event marker.
BIDS uses n/a to designate values that should be ignored.
The BIDS specification also mentions several optional columns, but validation of appropriate use is not done by the BIDS validator.
The exception is the optional HED column, which is used for event-specific
annotations and verified with the BIDS validator.
Users are also free to add their own columns to any events.tsv file.
This flexibility in the format of the events.tsv files is necessary
to accommodate the variety of possible events across the spectrum of BIDS datasets,
but it complicates data handling for downstream users,
who won’t know the meaning of these events.
Luckily, BIDS provides a mechanism for describing events in a machine-understandable, validated format using JSON sidecars and HED (Hierarchical Event Descriptors).
JSON event sidecars¶
The BIDS events.json files provide the BIDS mechanism for machine-actionable event processing,
meaning that downstream users can analyze the data with appropriate tools without writing
a lot of code.
Here is an excerpt from a BIDS events.json sidecar that is associated with the
above events.tsv excerpt.
{
"event_type": {
"Description": "The main category of the event.",
"HED": {
"setup_right_sym": "Experiment-structure, Condition-variable/Right-key-assignment",
"show_face": "Sensory-event, Experimental-stimulus, Visual-presentation, Image, Face",
"left_press": "Agent-action, Participant-response, (Press, Keyboard-key)",
"show_circle": "Sensory-event, (White, Circle), (Intended-effect, Cue)"
},
"Levels": {
"setup_right_sym": "Right index finger key press means above average symmetry.",
"show_face": "Display a stimulus face image.",
"left_press": "Participant presses a key with left index finger.",
"show_circle": "Display a white circle on black background."
}
},
"face_type": {
"Description": "Factor indicating type of face image being displayed.",
"Levels": {
"famous_face": "A face that should be recognized by the participants.",
"unfamiliar_face": "A face that should not be recognized by the participants.",
"scrambled_face": "A scrambled face image generated by taking face image 2D FFT."
},
"HED": {
"famous_face": "(Condition-variable/Famous-face, (Image, (Face, Famous)))",
"unfamiliar_face": "(Condition-variable/Unfamiliar-face, (Image, (Face, Unfamiliar)))",
"scrambled_face": "(Condition-variable/Scrambled-face, (Image, (Face, Disordered)))"
}
},
"stim_file": {
"Description": "Filename of the presented stimulus image.",
"HED": "(Image, Pathname/#)"
}
}
The JSON sidecar is a dictionary, where the keys correspond to column names.
In the above example, we have provided annotations for the columns
event_type, face_type, and stim_file.
The values corresponding to these keys are dictionaries
of relevant metadata about the corresponding columns.
Several columns in the events.tsv file do not have keys in the JSON sidecar
(onset, duration, sample, rep_status, trial, rep_lag, value)
because we have chosen not to provide information about these columns.
The Description fields provide information about the general meanings
of the corresponding columns.
The Levels fields provide information about individual categorical values
within a column in a human-readable form.
The HED sidecar fields contain descriptive tags from a controlled vocabulary,
which can be read and processed by computer algorithms.
At analysis time, tools are available to assemble the HED annotations for each event.
For example the relevant HED tags for the second event in the excerpted event file are:
show_face: Sensory-event, Experimental-stimulus, Visual-presentation, Image, Face
unfamiliar_face: (Condition-variable/Unfamiliar-face, (Image, (Face, Unfamiliar)))
stim_file: (Image, Pathname/#)
The stim_file column has been annotated as a value column rather a categorical column,
so the HED tags corresponding to that column are assembled by substituting the actual column
value in the events.tsv file for the # tag placeholder.
HED tools can assemble the complete annotation for each event from the event file
and its accompanying JSON sidecar.
The standardized HED vocabulary allows tools to search for events with common tags across datasets.
We recommend that when at all possible, you place your HED annotations in a single JSON sidecar file located in the root directory of your BIDS dataset.
Do not use the HED column in the individual events.tsv unless you
really need to annotate events individually, because
individual event annotation is a lot more work and harder to maintain.
The next section guides you through the creation of a JSON sidecar for event annotation using convenient online tools.
The Basic HED Annotation tutorial walks you through the process of selecting HED tags for annotation.
Create a JSON template¶
As described in the previous section, users provide metadata about events
in a JSON sidecar.
This tutorial demonstrates how to use online tools to generate a JSON sidecar template
by extracting information from one of the events.tsv files in your BIDS dataset.
Once the skeleton of the JSON sidecar is in place,
and you just need to edit in your specific metadata.
Working from a template is much easier and faster than creating a sidecar from scratch. Using the HED events online tools, the steps to create a template are:
You can then edit your JSON sidecar directly or convert it to a spreadsheet to fill in the annotations.
Step 1: Select generate JSON¶
Go to the Events page of the HED online tools. You will see the following menu:
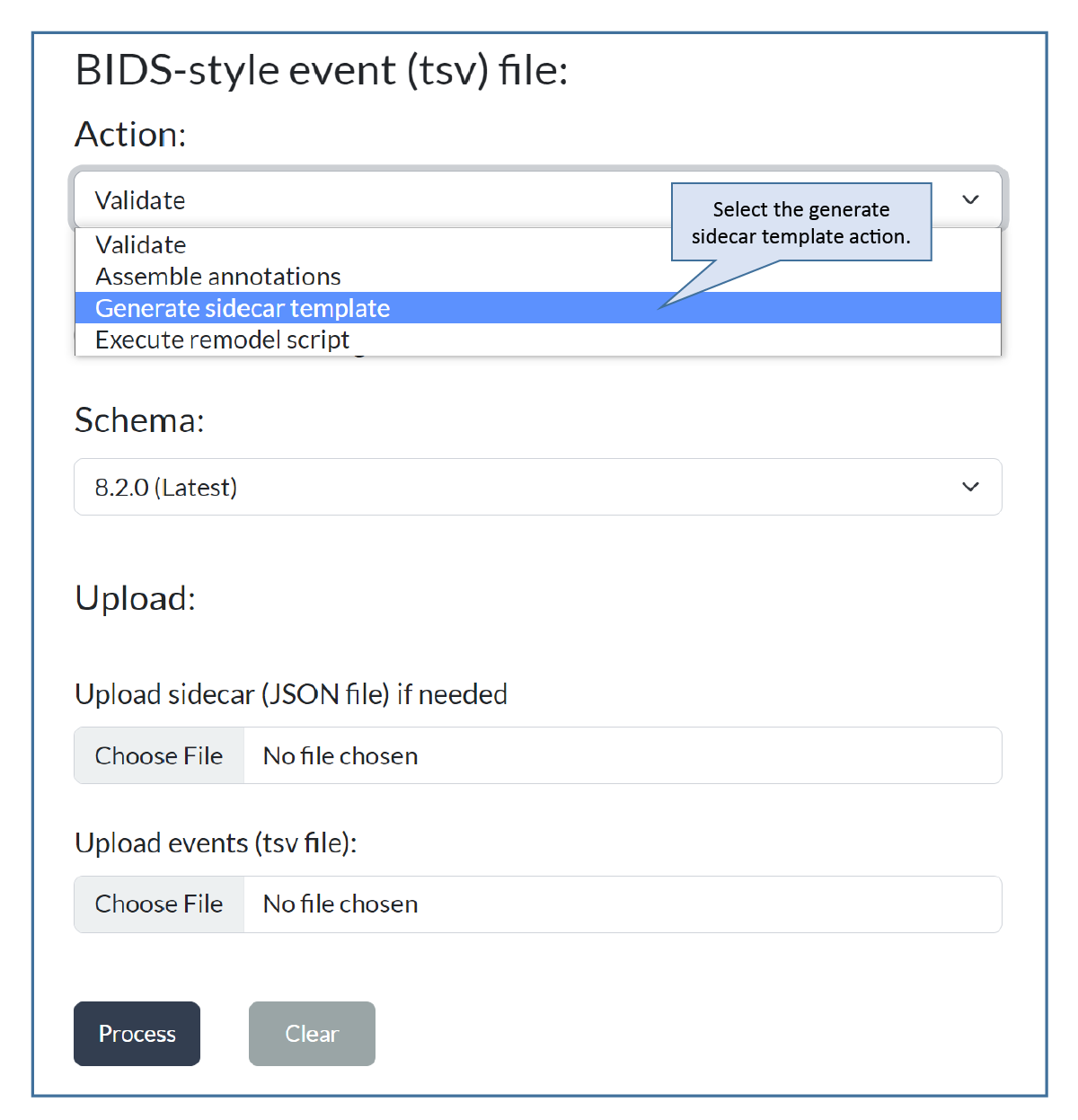
Select Generate sidecar template. The application will adjust to your selection, showing only the information you need to provide.
Step 2: Upload an events file.¶
Use the Browse button to choose an events.tsv file to upload.
When the upload is complete, the local file name of the uploaded events
file will be displayed next to the Browse button.
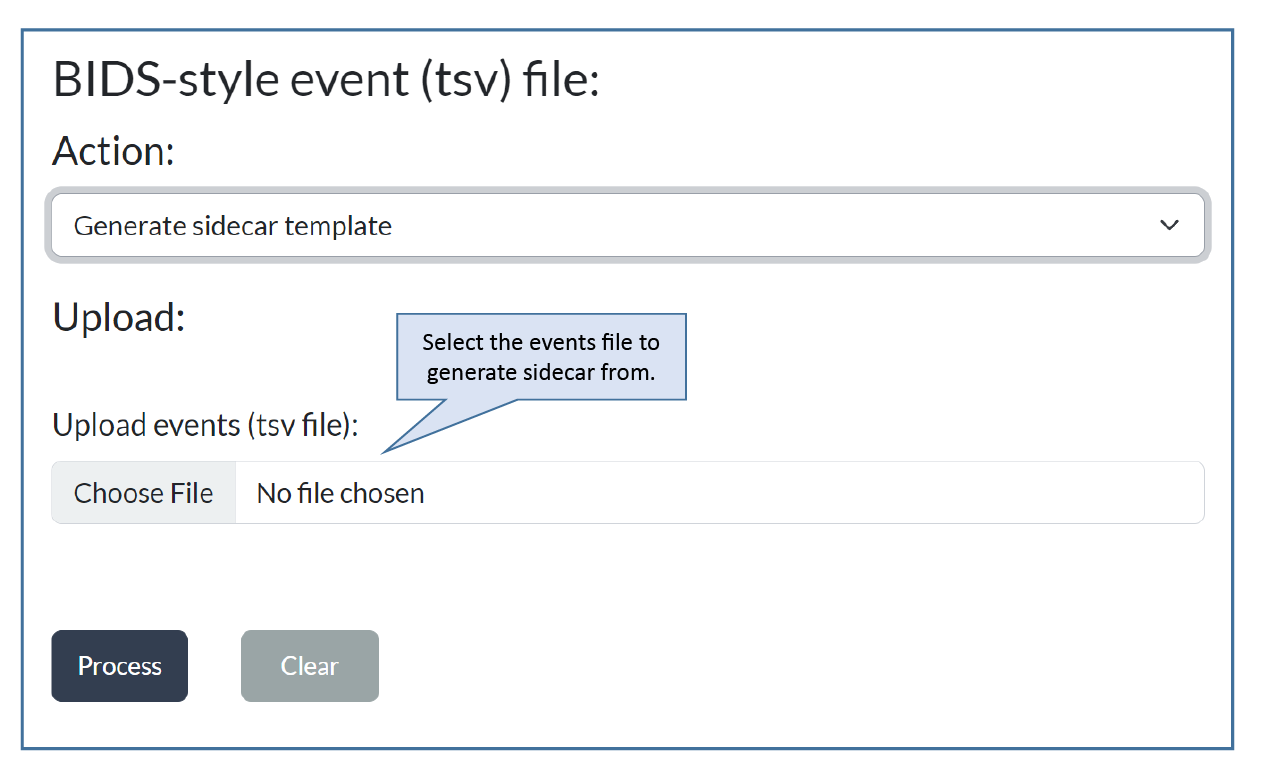
In this example, we have uploaded sub-002_task-FacePerception_run-1_events.tsv. Here is a simplified excerpt from the beginning of this file:
A simplified excerpt from a BIDS event file.
onset |
duration |
sample |
event_type |
face_type |
rep_status |
trial |
rep_lag |
value |
stim_file |
|---|---|---|---|---|---|---|---|---|---|
0.004 |
n/a |
1.0 |
setup_right_sym |
n/a |
n/a |
n/a |
n/a |
3 |
n/a |
24.2098 |
n/a |
6052 |
show_face |
unfamiliar_face |
first_show |
1 |
n/a |
13 |
u032.bmp |
25.0353 |
n/a |
6259 |
show_circle |
n/a |
n/a |
1 |
n/a |
0 |
circle.bmp |
25.158 |
n/a |
6290 |
left_press |
n/a |
n/a |
1 |
n/a |
256 |
n/a |
… |
When the upload is complete, the application will expand to show
the columns present in the uploaded events.tsv file.
Step 3: Select columns to annotate¶
Annotations consist of descriptions of the values in the
events.tsv file as well as associated HED tags that allow computer tools
to directly process these.
You will use the summary information provided about the columns in the events.tsv file
to decide which columns should be annotated.
The checkboxes on the left indicate which columns should be included in the JSON sidecar annotation template.
The checkboxes on the right indicate which event file columns contain values that you wish to annotate individually. We refer to these columns as the categorical columns.
The numbers in parentheses next to the column names give the number of unique values in each column. You will not want to treat columns with a large number of unique values as categorical columns, since you will need to provide an individual annotation for each value in such a categorical column.
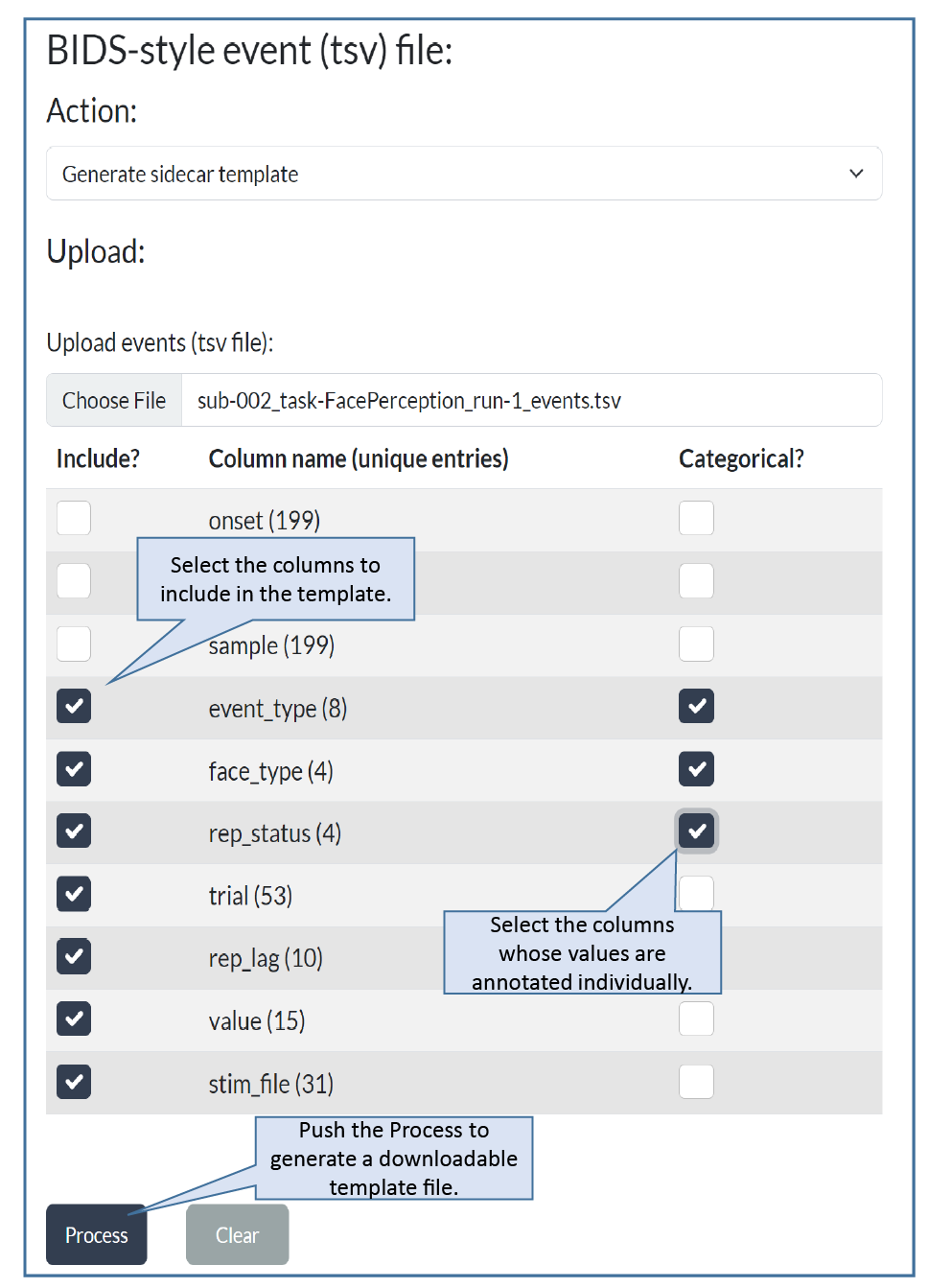
In the example, we have selected 7 columns to annotate.
We omitted the onset, duration, and sample columns,
since these columns have standardized meanings.
The duration column has only 1 unique value because this particular
dataset has n/a for all entries.
We have selected the event_type, face_type, and rep_status columns
as categorical columns, meaning that we will annotate each unique
value in these columns in a separate annotation.
The event_type, face_type, and rep_status have a total of 16 unique values.
In addition, we have elected to annotate trial, rep_lag, value, and stim_file
by describing these columns as a whole, resulting in 4 additional annotations.
In all, we will have to provide a total of 8 + 4 + 4 + 1 + 1 + 1 + 1 = 20 HED annotations based on the selections we have made.
Step 4: Download the template.¶
After you press the Process button, the online tools produce a JSON template file for you download. Save the file, and you are ready to begin the actual annotation. You can edit the JSON sidecar using a text editor or other appropriate tool.
The sub-002_task-FacePerception_run-1_events.tsv file generates this JSON sidecar template. The following is a simplified excerpt of this template, which we will use to illustrate the rest of the annotation process.
JSON sidecar generated template.
{
"event_type": {
"Description": "Description for event_type",
"HED": {
"setup_right_sym": "(Label/event_type, Label/setup_right_sym)",
"left_press": "(Label/event_type, Label/left_press)",
"show_face": "(Label/event_type, Label/show_face)",
"show_circle": "(Label/event_type, Label/show_circle)"
},
"Levels": {
"setup_right_sym": "Description for setup_right_sym of event_type",
"left_press": "Description for left_press of event_type",
"show_face": "Description for show_face of event_type",
"show_circle": "Description for show_circle of event_type"
}
},
"stim_file": {
"Description": "Description for stim_file",
"HED": "(Label/stim_file, Label/#)"
}
}
Notice the difference in structure between annotations for columns
that are designated as categorical columns (such as event_type)
and columns that are designated as value columns (such as stim_file).
The HED annotations for the non-categorical value columns must contain a #
so that the individual column values can be substituted for the # placeholder
when the annotation is assembled.
Step 5: Complete the annotation.¶
Once you have a JSON sidecar template, you should edit in your event annotations. The following is an edited version of the simplified template excerpt containing a minimal set of HED annotations.
JSON sidecar with completed annotation.
{
"event_type": {
"Description": "The main category of the event.",
"HED": {
"setup_right_sym": "Experiment-structure, Condition-variable/Right-key-assignment",
"left_press": "Agent-action, Participant-response, (Press, Keyboard-key)",
"show_face": "Sensory-event, Experimental-stimulus, Visual-presentation, Image, Face",
"show_circle": "Sensory-event, (White, Circle), (Intended-effect, Cue)"
},
"Levels": {
"setup_right_sym": "Right index finger key press means above average symmetry.",
"left_press": "Participant presses a key with left index finger.",
"show_face": "Display a stimulus face image.",
"show_circle": "Display a white circle on black background."
}
},
"stim_file": {
"Description": "Filename of the presented stimulus image.",
"HED": "(Image, Pathname/#)"
}
}
If you feel comfortable working with JSON files you can edit the HED annotations and descriptions directly in the JSON file.
The HED annotations in the examples are minimal to simplify the explanations. See Basic HED Annotation for guidelines on how to select HED tags.
Once you have finished, you should validate your JSON file to make sure that your annotations are correct. See the HED validation guide for detailed guidance. When you are satisfied with your valid JSON sidecar, simply upload it to the root directory of your BIDS dataset, and you are done.
If you would rather work with spreadsheets when doing your annotations, you can extract a spreadsheet from the JSON sidecar to edit and merge back after you are finished. This process is described in the next section, which you can skip if you are going to edit the JSON directly.
Spreadsheet templates¶
Many people find working with a spreadsheet of annotations easier than direct editing a JSON events sidecar file. The HED online tools provide an easy method for converting between a JSON sidecar and a spreadsheet representation.
You can convert the JSON events sidecar file into a spreadsheet for easier editing and then convert back to a JSON file afterwards. This tutorial assumes that you already have a JSON events sidecar or have extracted a JSON sidecar template.
Using the HED sidecar online tools, the steps to create a template are:
Step 1: Select extract HED spreadsheet¶
Go to the Sidecar page of the HED online tools. You will see the following menu:
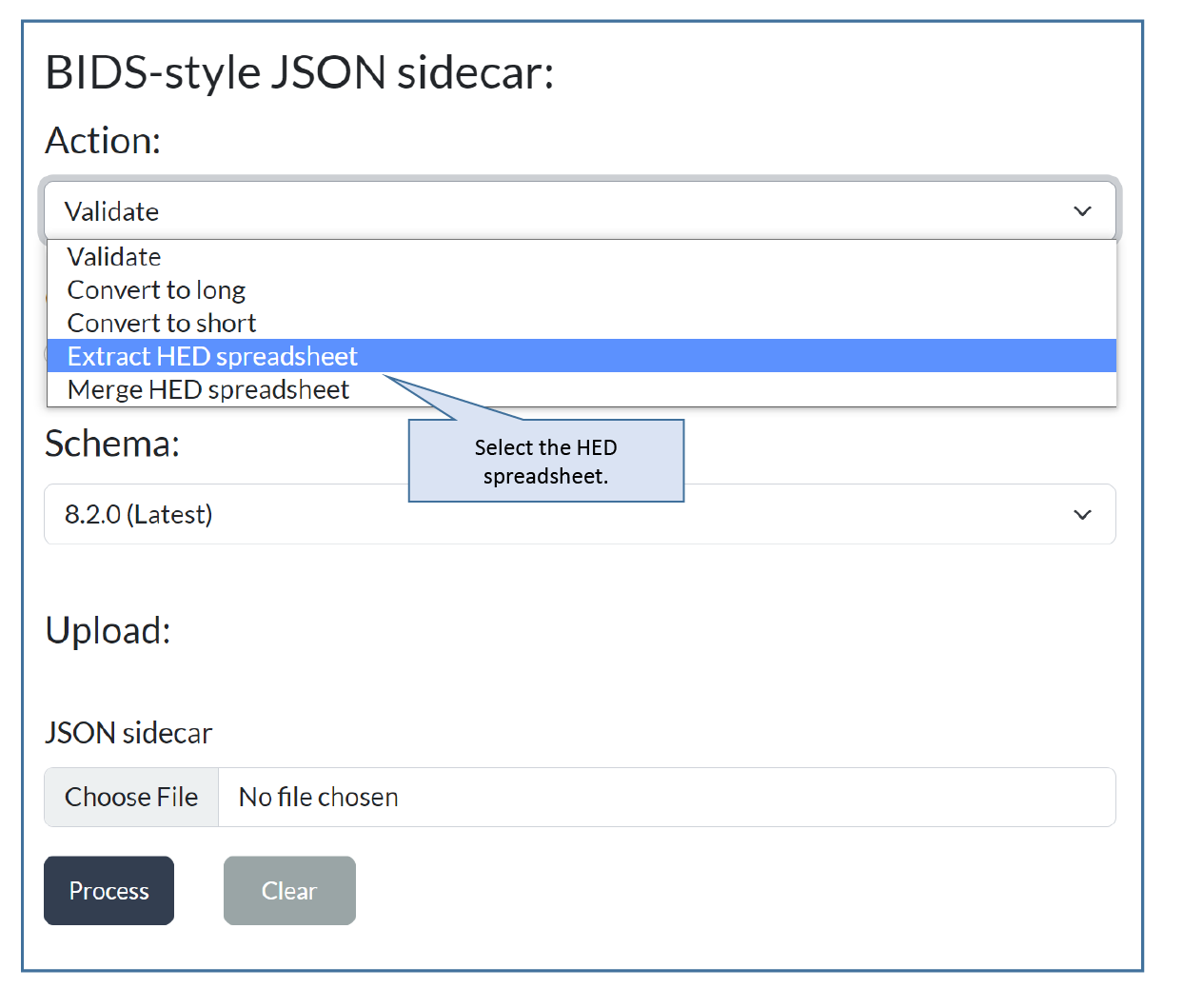
Select Extract HED spreadsheet. The application will adjust to your selection, showing only the information you need to provide.
Step 2: Upload a sidecar and extract.¶
Use the Browse button to choose an events.json file to upload.
When the upload is complete, the local file name of the uploaded events
file will be displayed next to the Browse button.
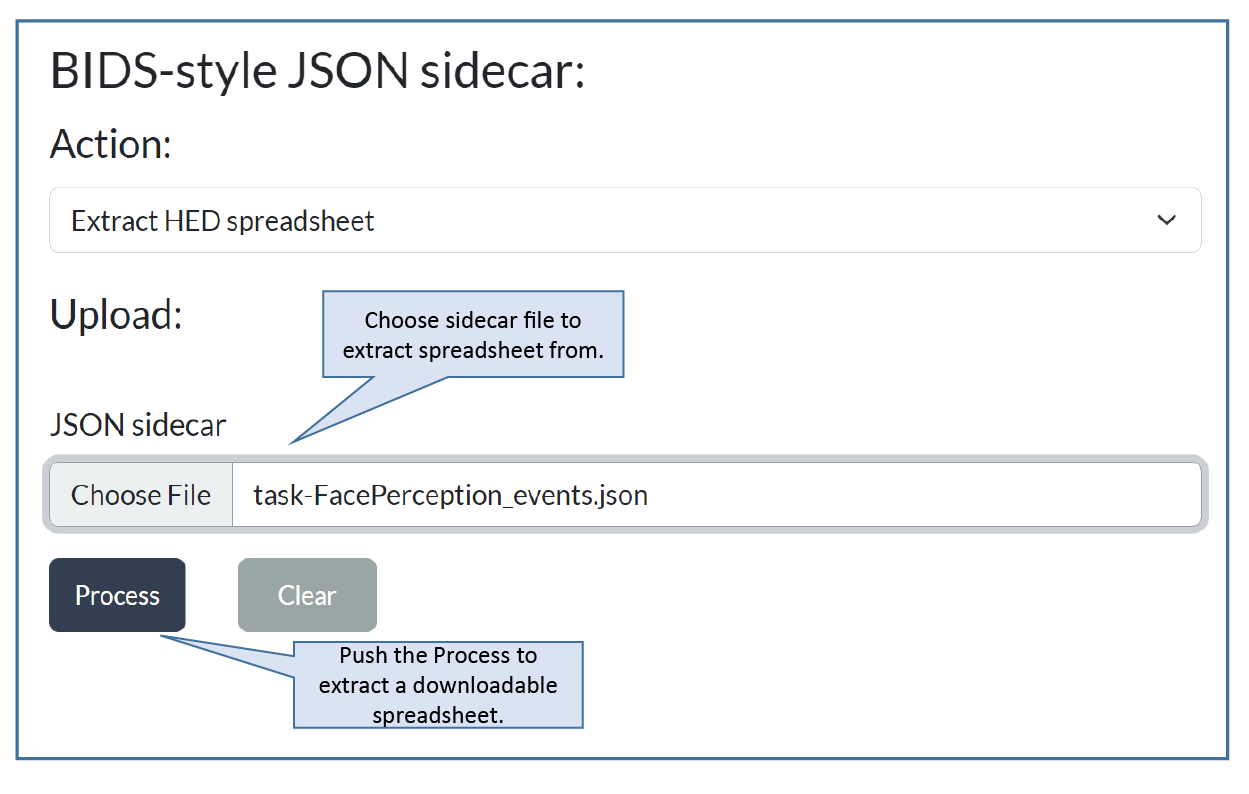
Pressing the Process button causes the application to generate a downloadable tab-separated-value spreadsheet for editing
An excerpt from the spreadsheet generated from the extracted JSON file is:
HED annotation table extracted from JSON sidecar template.
column_name |
column_value |
description |
HED |
|---|---|---|---|
event_type |
setup_right_sym |
Description for setup_right_sym |
(Label/event_type, |
event_type |
show_face |
Description for show_face |
(Label/event_type, |
event_type |
left_press |
Description for left_press |
(Label/event_type, |
event_type |
show_circle |
Description for show_circle |
(Label/event_type, |
stim_file |
n/a |
Description for stim_file |
Label/# |
The spreadsheet has 4 columns: the column_name corresponds to the column
name in the events.tsv file.
The column_value corresponds to one of the unique values within that column.
The description column is used to fill in the corresponding Levels value,
while the HED column is used for the
HED
tags that make your annotation machine-actionable.
These tags are from the corresponding HED entry in the sidecar.
The last row of the excerpt has stim_file as the column_name.
This column was not selected as a categorical column when the sidecar template was created.
The column_value for such columns is always n/a.
The description column is used for the Description value in the sidecar.
The HED column tags must include a # placeholder in this case.
During analysis the column value is substituted for the #
when the HED annotation is assembled.
Step 3: Edit the spreadsheet¶
After saving the file, you are free to edit it in a text editor
or in a tool such as Excel.
You may save the edited spreadsheet in either .tsv or .xslx format.
The following is the extracted spreadsheet corresponding to the edited JSON sidecar above.
HED annotation table extracted from JSON sidecar template.
column_name |
column_value |
description |
HED |
|---|---|---|---|
event_type |
setup_right_sym |
Right index finger key press |
Experiment-structure, |
event_type |
show_face |
Display a stimulus face image. |
Sensory-event, Experimental-stimulus, |
event_type |
left_press |
Participant presses key |
Agent-action, Participant-response, |
event_type |
show_circle |
Display a white circle |
Sensory-event, (White, Circle), |
stim_file |
n/a |
Filename of the presented |
(Image, Pathname/#) |
If you wish a particular table cell to be ignored, use n/a in the cell.
Step 4: Merge the spreadsheet¶
Although editing metadata in a spreadsheet is convenient, BIDS stores all of its metadata in JSON files. If you choose to extract a spreadsheet for editing your annotations, you will need to merge the edited spreadsheet back into a JSON sidecar before including it in your BIDS dataset.
Using the HED sidecar online tools, select merge HED spreadsheet as shown below. You may choose an existing edited sidecar, the original template, or an empty sidecar as the JSON target file for the merge.
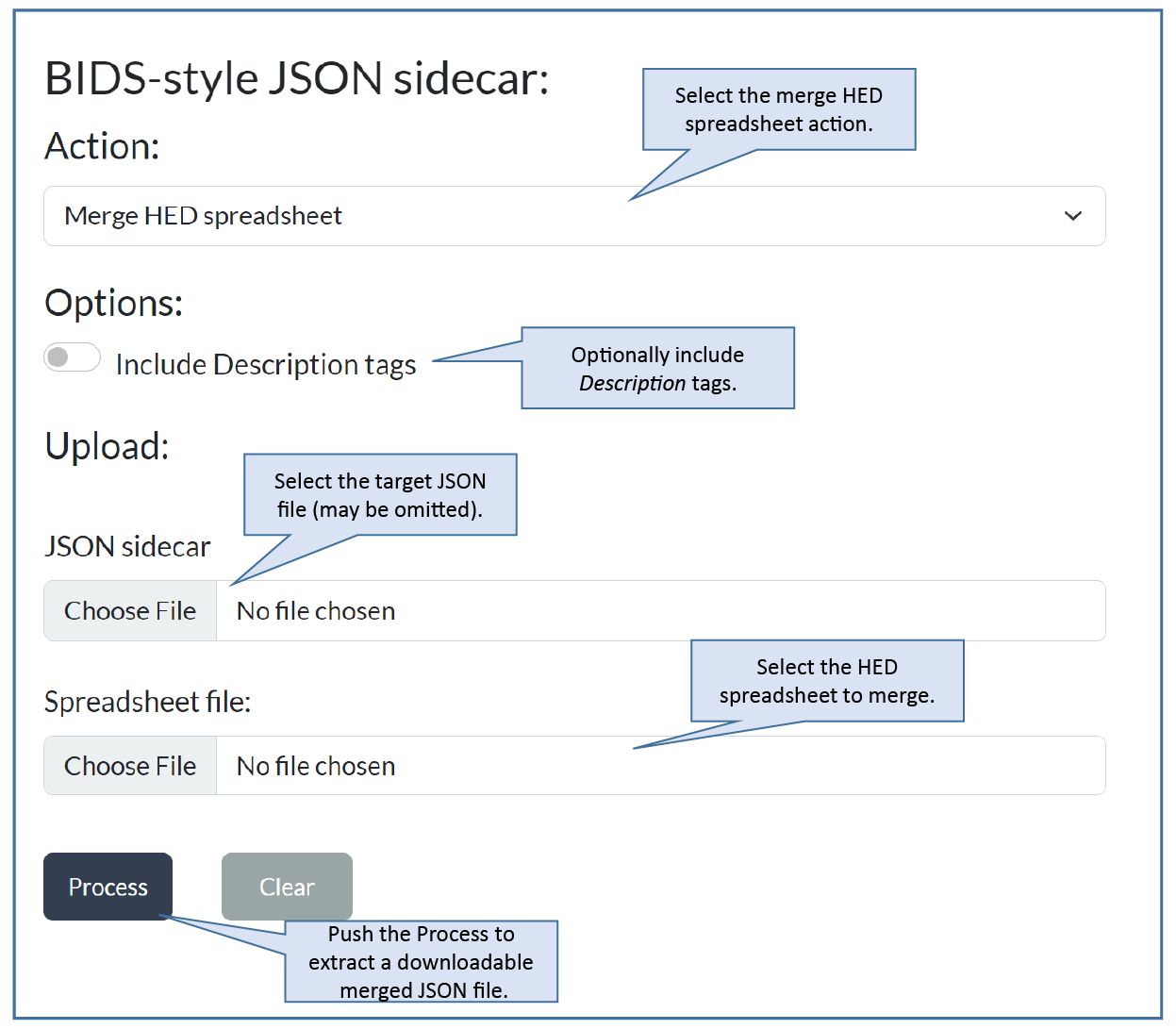
Pressing the Process button causes the application to generate a downloadable version of the merged JSON file.
The merging process replaces the HED section of the JSON file for a
specified column name and column value with the tags in the corresponding
HED column of the spreadsheet.
Similarly, merging replaces the Levels section of the JSON file for a
specified column name and column value with the description in the corresponding
description column of the spreadsheet.
For value columns, the description replaces the value of the Description
entry corresponding to that column.
Since the BIDS JSON sidecar files may contain other information besides
HED annotations,
the merging process tries to preserve the sidecar entries that are not
directly related to the HED annotations.
The merging process also ignores description and HED spreadsheet entries
containing n/a.
Notice that there is an option to include Description tags when doing the merge. If this box is checked, the contents of the description field are prepended with the Description tag and appended to the tags.